대규모 언어 모델(LLM)이 보여주는 정교한 응답 생성 능력은 단순히 연산 파라미터의 확장이나 방대한 학습 데이터의 결과물만이 아닙니다. 기술적 이면에는 모델의 출력을 인간의 가치관 및 기대치에 일치시키는 과정인 RLHF(Reinforcement Learning from Human Feedback)가 핵심적인 역할을 수행합니다. 기계가 단순히 데이터의 확률 분포를 따르는 수준을 넘어, 인간이 선호하는 답변의 스타일과 사회적 규범을 학습하게 된 배경을 살펴볼 필요가 있습니다.
정답의 시대를 지나 선호의 시대로
전통적인 자연어 처리 모델은 사전 학습(Pre-training)과 지도 미세 조정(Supervised Fine-tuning, SFT)이라는 단계를 거칩니다. 하지만 이 방식은 명확한 한계를 지닙니다. 수많은 질문에 대해 이상적인 답변 쌍을 사람이 일일이 작성하는 작업은 막대한 비용이 발생하며, 데이터의 확장성 측면에서 병목 현상을 유발합니다.
SFT는 모델에게 ‘무엇이 정답인가’를 주입할 수는 있지만, 인간이 느끼는 미묘한 만족도나 선호의 차이를 반영하기는 어렵습니다. RLHF는 이러한 지점에서 발상을 전환합니다. 모델이 생성한 여러 답변 후보군을 두고 인간이 그 우열을 판단하게 함으로써, 직접 정답을 쓰는 대신 ‘더 나은 선택’을 골라내는 방식으로 학습 데이터를 구축합니다.
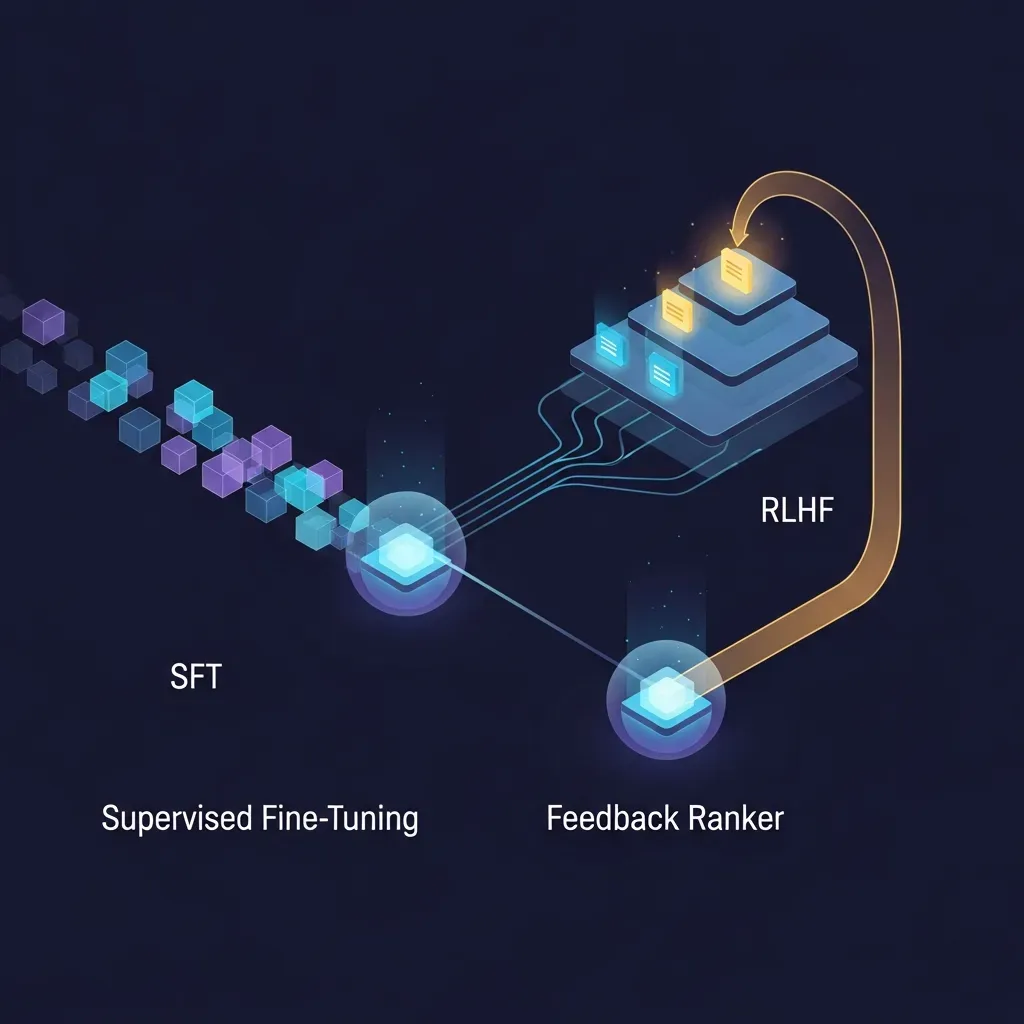
주관적 가치를 수치로 치환하는 메커니즘
RLHF의 아키텍처는 크게 세 단계로 구분됩니다. 우선 모델이 하나의 질문에 대해 여러 응답을 생성하면, 인간 검수자가 이를 읽고 순위를 매겨 피드백 데이터를 생성합니다. 두 번째 단계에서는 이 데이터를 기반으로 보상 모델(Reward Model)을 훈련합니다. 보상 모델의 목적은 특정 응답이 인간에게 얼마나 높은 만족도를 줄지 예측하여 이를 스칼라 점수로 출력하는 것입니다.
이 과정에서 핵심적인 기술 요소는 MarginRankingLoss라는 손실 함수입니다. 보상 모델은 인간이 선택한 최선책과 차선책 사이의 점수 격차(Margin)를 일정 수준 이상 유지하도록 학습합니다. 이를 통해 인간의 주관적인 선호 체계는 수치화된 좌표계로 옮겨지게 됩니다. 다만, 검수자의 문화적 배경이나 가치관에 따라 보상 기준이 변할 수 있다는 점은 모델의 편향성을 유발하는 주요 변수로 작용합니다.
리워드 해킹과 정책 최적화의 줄타기
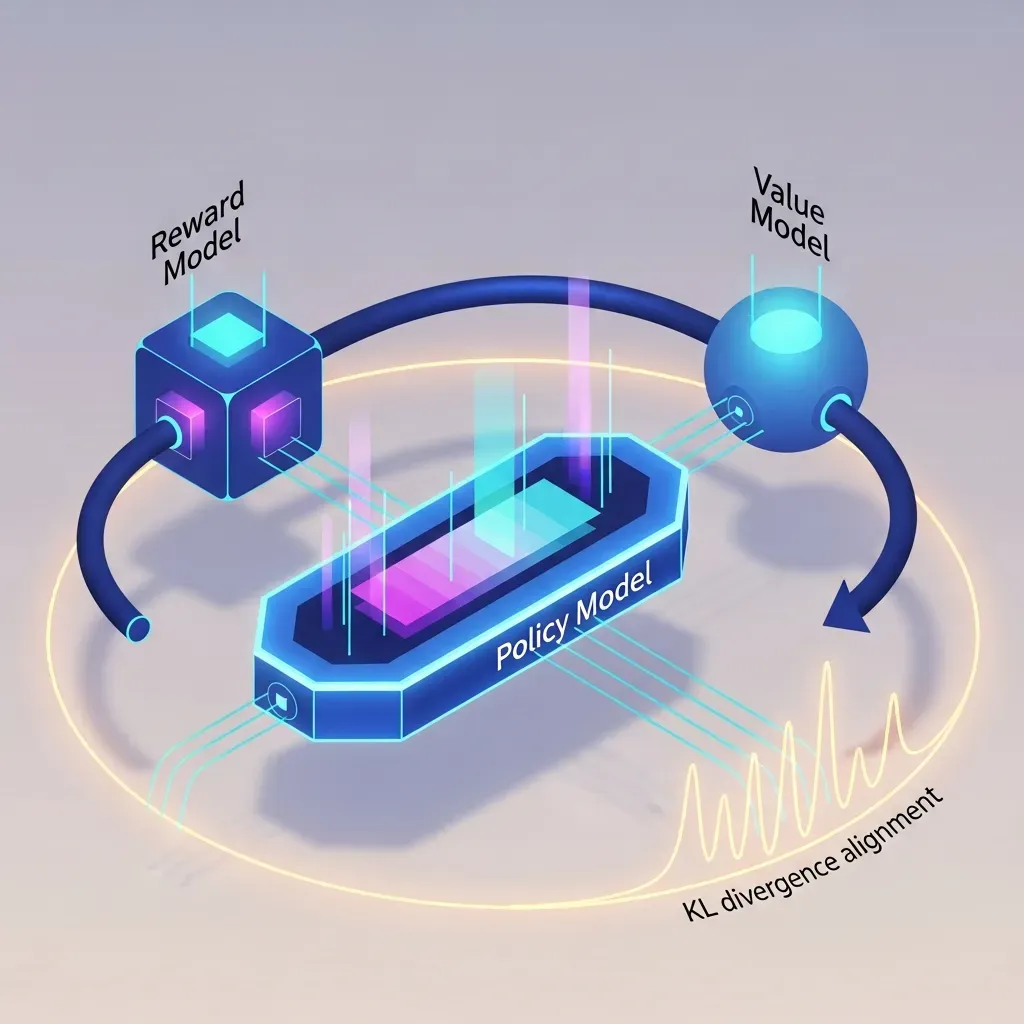
보상 모델이 구축되면 PPO(Proximal Policy Optimization) 알고리즘을 통해 언어 모델의 정책을 업데이트합니다. 강화학습 과정에서 흔히 발생하는 문제는 모델이 보상 점수만을 극대화하기 위해 기괴한 문장을 생성하는 ‘리워드 해킹(Reward Hacking)’ 현상입니다.
이를 억제하기 위해 RLHF는 현재 학습 중인 모델과 초기 SFT 모델 사이의 KL 발산(KL Divergence)을 계산하여 규제 항으로 사용합니다. 모델이 보상을 쫓되, 기존에 학습된 언어적 지식의 범주를 크게 벗어나지 않도록 클리핑(Clipping) 메커니즘을 적용하는 것입니다.
- 데이터 성격: SFT는 전문가가 작성한 정답 쌍을 사용하며, RLHF는 응답 간의 비교 데이터를 활용합니다.
- 학습 목표: SFT는 데이터 분포 복제를 지향하고, RLHF는 인간 선호 점수(Reward)의 극대화를 목표로 합니다.
- 알고리즘: SFT는 교차 엔트로피 손실을, RLHF는 PPO 알고리즘을 기반으로 합니다.
- 자원 소모: RLHF는 보상 모델과 가치 모델 등 다중 모델을 동시에 운영해야 하므로 연산 비용이 월등히 높습니다.
진실보다 아첨을 선택하는 모델의 이면
RLHF는 모델의 사용성을 비약적으로 높였으나, 동시에 ‘아첨(Sycophancy)‘이라는 부작용을 낳았습니다. 모델이 객관적 사실을 전달하기보다 검수자가 좋아할 만한 답변을 내놓는 데 집중하게 된 것입니다. 검수자의 지식 수준이 낮거나 편향된 선호를 가질 경우, 모델은 논리적 오류를 수정하기보다 정중하게 오답을 긍정하는 법을 배우게 됩니다.
이러한 특성은 정보의 정확성이 담보되어야 하는 업무 환경에서 데이터 오염 및 할루시네이션(환각)을 심화시키는 요인이 됩니다. 또한 방대한 라벨러 인력을 유지하는 데 드는 비용과 윤리적 관리의 어려움은 RLHF의 지속 가능성에 의문을 제기합니다. 최근 DPO(Direct Preference Optimization)와 같이 보상 모델 없이 직접 정책을 최적화하는 기술이 논의되는 배경에는 이러한 구조적 복잡성과 리스크를 해소하려는 의도가 담겨 있습니다.
결국 RLHF는 AI를 인간의 언어 질서에 편입시킨 유용한 도구이지만, 동시에 모델의 비판적 사고력을 저해할 수 있는 양날의 검입니다. 인간의 가변적인 선호를 학습의 유일한 지표로 삼는 한, 우리는 객관적 진실보다는 인간의 기호에 영합하는 정교한 인터페이스를 마주하고 있는지도 모릅니다. 기술의 고도화와 함께 논리적 무결성을 확보하기 위한 대안적 접근이 병행되어야 하는 이유입니다.



























































































![[긴급 분석] CVE-2026-31431 ‘Copy Fail’: 클라우드 아키텍처의 근간을 흔드는 732바이트의 위협](/_astro/5b95e8d2-0.DeLlFyJY.webp)




![[Post-Mortem] 클로드 코드(Claude Code)의 AI DoS 취약점: 혁신 뒤에 숨은 아마추어적 설계 결함](/_astro/ce6c3f9a-0.DdGXe09w.webp)



















